Show code
df = get_df("data/2_processed")
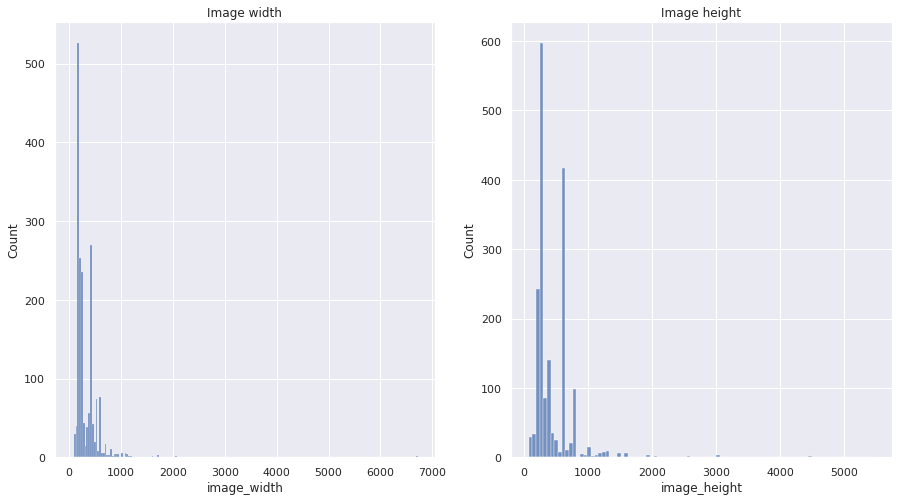
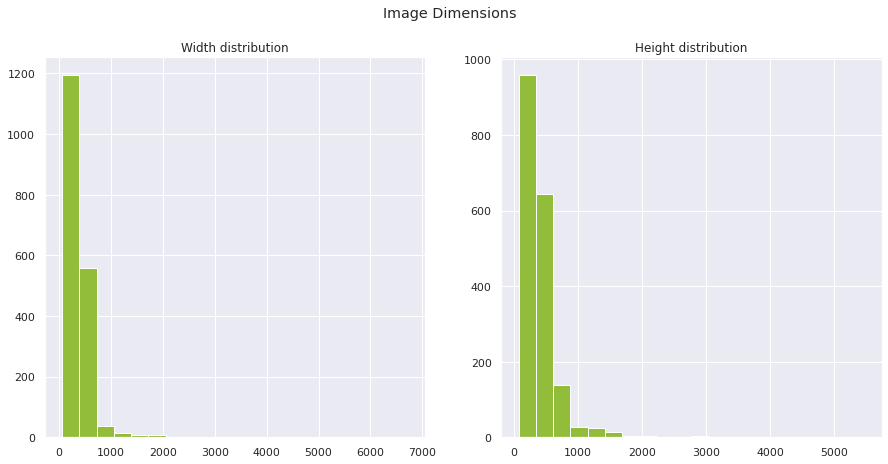
df['dimensions'] = df['file_path'].apply(lambda x: get_dims(x))
df['image_width'] = df['dimensions'].apply(lambda x: x[0] if x is not None else None)
df['image_height'] = df['dimensions'].apply(lambda x: x[1] if x is not None else None)
df['pixels'] = df['image_width'] * df['image_height']
df['corrupt_status'] = df['file_path'].apply(lambda x: check_corrupted(x))
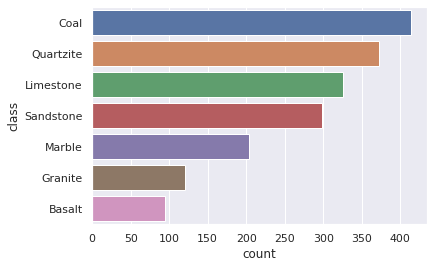
df.head(5)| file_name | class | file_path | file_type | dimensions | image_width | image_height | pixels | corrupt_status | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | dataset1_Limestone_147_23.jpg | Limestone | data/2_processed/Limestone/dataset1_Limestone_... | .jpg | (285, 380) | 285.0 | 380.0 | 108300.0 | False |
| 1 | dataset2_Limestone_418_Limestone521.jpg | Limestone | data/2_processed/Limestone/dataset2_Limestone_... | .jpg | (225, 225) | 225.0 | 225.0 | 50625.0 | False |
| 2 | dataset1_Limestone_315_78.jpg | Limestone | data/2_processed/Limestone/dataset1_Limestone_... | .jpg | (408, 612) | 408.0 | 612.0 | 249696.0 | False |
| 3 | dataset1_Limestone_078_168.jpg | Limestone | data/2_processed/Limestone/dataset1_Limestone_... | .jpg | (408, 612) | 408.0 | 612.0 | 249696.0 | False |
| 4 | dataset1_Limestone_305_69.jpg | Limestone | data/2_processed/Limestone/dataset1_Limestone_... | .jpg | (408, 612) | 408.0 | 612.0 | 249696.0 | False |